Data doesn’t fail. Data architectures do.
Data Warehouse, Data Lake, or Data Mesh? The difference between operational chaos and competitive advantage starts with how your organization structures, governs, and scales data.
Data Warehouse vs Data Lake vs Data Mesh
Storing data is no longer the challenge. Turning it into competitive advantage is. Organizations are generating more data than ever before. Internal systems, cloud platforms, CRMs, ERPs, IoT devices, social media, analytics platforms, artificial intelligence, everything produces data at massive scale. But there is a problem many companies still underestimate:
Having data does not mean having control. And it certainly does not mean having intelligence.

The real challenge starts after data collection
Many organizations continue investing heavily in technology while ignoring a fundamental question:
Where should data live? How should it be organized? And who should own it?
When these decisions are not made strategically, the outcome is predictable:
- Duplicate data
- Inconsistent reporting
- Misaligned teams
- Slow decision-making
- Low trust in information
And in a data-driven economy, that becomes a direct threat to competitiveness.
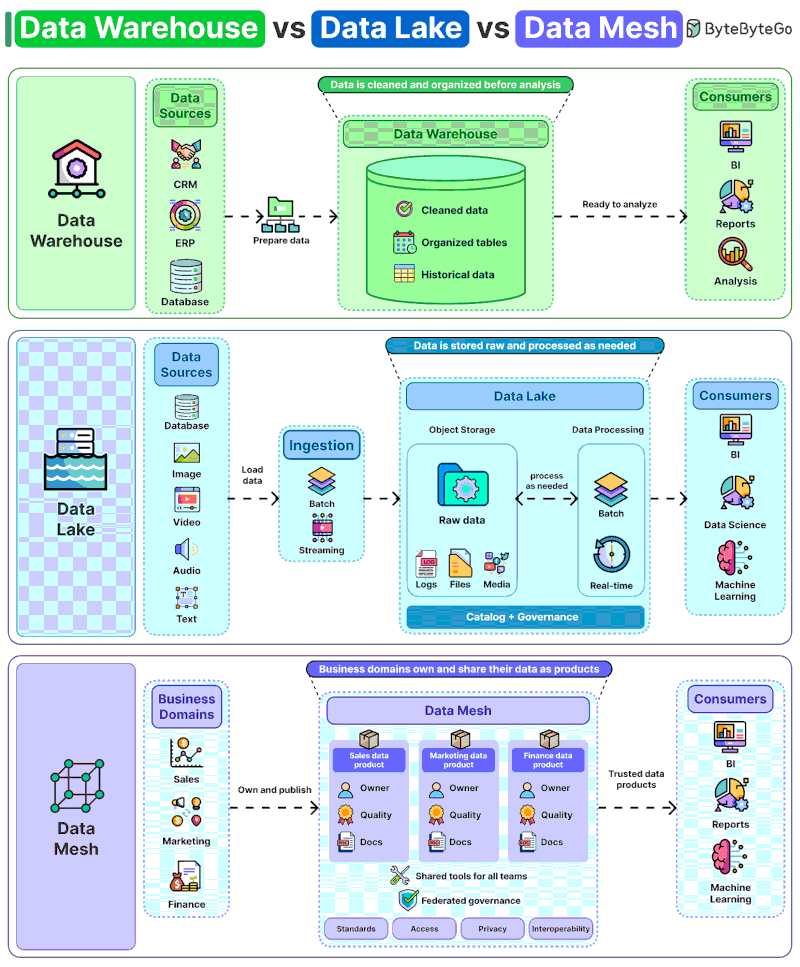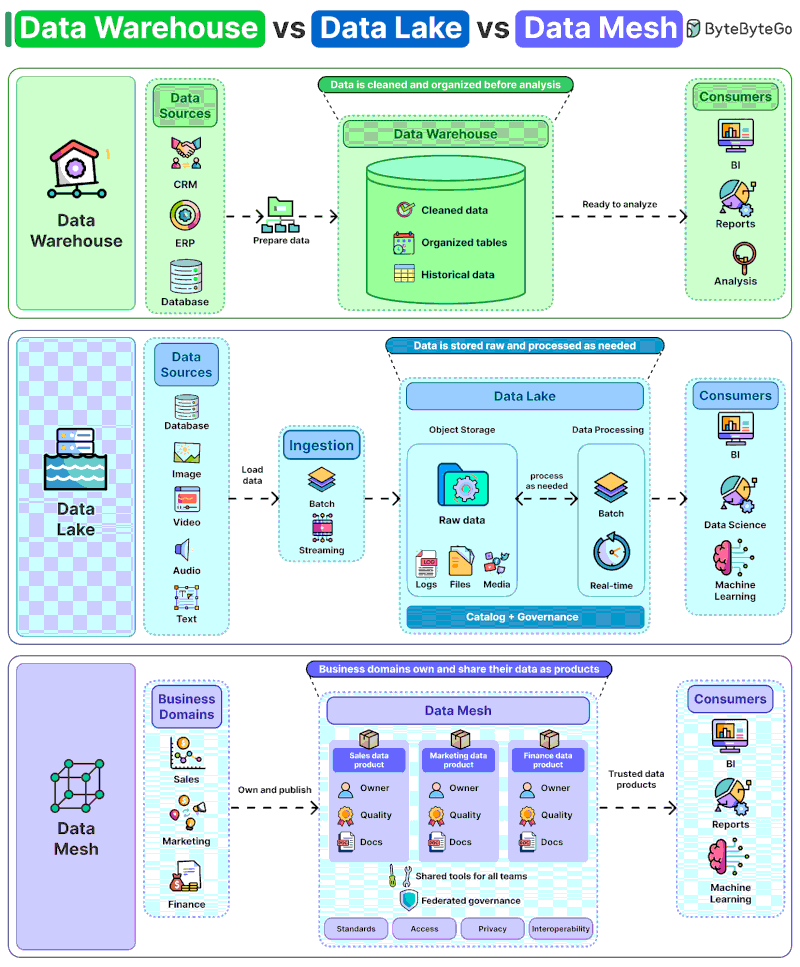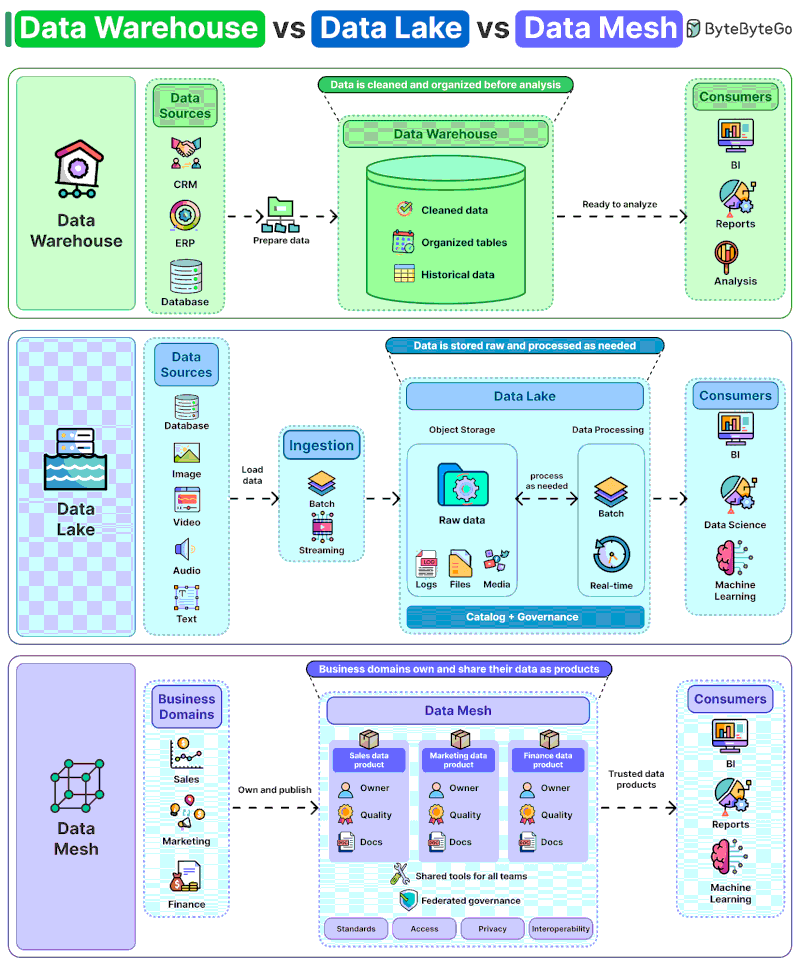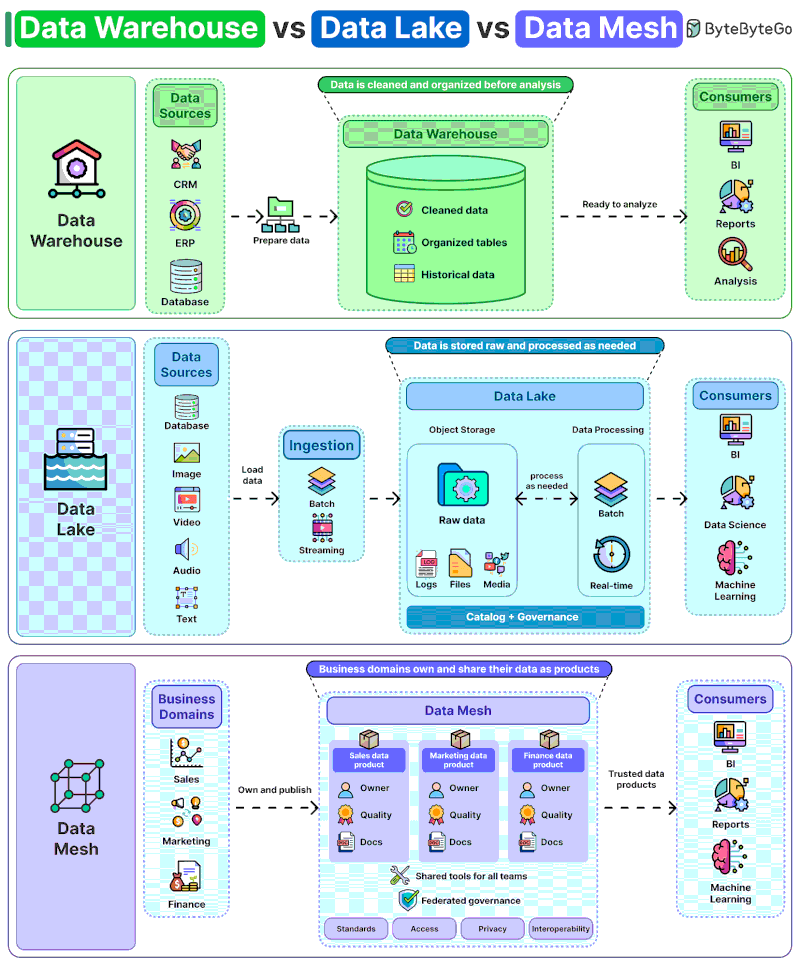
Data Warehouse: Structure, control, and consistency
The Data Warehouse remains the traditional choice for organizations that prioritize reliable reporting, consistent KPIs, and high-performance analytics. Data is cleaned, transformed, and structured before being stored. The result? Faster dashboards, aligned metrics, and greater confidence in business decisions.
But there is a trade-off. Every new data source requires additional modeling, integration, and governance effort. Scalability can become slower in highly dynamic environments.
Data Lake: Maximum flexibility. But without governance, chaos follows.
The Data Lake emerged as a response to the explosion of modern data. Logs, videos, images, documents, sensors, databases, everything can be stored in raw format. The flexibility is powerful. Especially for AI, Machine Learning, and Advanced Analytics workloads.
The problem? Without strong governance, naming standards, ownership, and quality controls, a Data Lake quickly becomes a Data Swamp.
Outdated, duplicated, undocumented data that becomes difficult, or impossible, to trust and reuse. What was supposed to create agility often creates operational complexity instead.
Data Mesh: Scaling data through teams
The Data Mesh introduces a major shift in mindset. Instead of relying on a centralized data team, each business domain becomes responsible for its own data products.
- Sales owns sales data
- Finance owns financial data
- Marketing owns campaign data
All supported by shared interoperability and governance standards. The model is powerful. Especially for large-scale organizations.
But it also requires maturity. Because decentralizing data without the right people, processes, and accountability can amplify problems instead of solving them.
The reality? There is no single winning approach.
The most mature organizations already understand this:
Data Warehouse, Data Lake, and Data Mesh are not competing models. They are complementary strategies
In practice:
- Data Warehouses support dashboards and executive reporting
- Data Lakes power AI and Machine Learning workloads
- Data Mesh enables scalable ownership and team autonomy
The real competitive advantage does not come from choosing a single technology. It comes from designing a data architecture aligned with business strategy.
The future belongs to organizations that turn data into decisions
Data is no longer just a technical asset. It is an accelerator for innovation, efficiency, and growth. And organizations that continue treating data architecture as a purely technical discussion will lose speed in a market increasingly driven by intelligence, automation, and AI.
The question is no longer: “Where do we store data?”
The real question is: “How do we transform data into a scalable system for decision-making and competitive advantage?”